I saggi pubblicati su Tangram
Robot che imparano

Tangram, anno IV n° 11 (settembre 2005)
Negli anni '60 dello scorso secolo, quando l'informatica era giovane, sulla scia dei contributi di Turing, Shannon, Minski ad altri iniziò a svilupparsi quella disciplina che in seguito si sarebbe chiamata "intelligenza artificiale" ma all'epoca veniva ancora denominata cibernetica. In quel periodo la discussione sulla possibile "intelligenza" delle macchine, pur sempre specialistica, era tuttavia assai meno esoterica allora di quanto lo è oggigiorno: si iniziava infatti appena ad esaminare le basi astratte della conoscenza e si discuteva, magari in modo ancora un po' ingenuo, della reale possibilità di costruire sistemi che "capissero", almeno nel senso dato da Turing a questo termine. Vale la pena di ricordare che a quell'epoca solo le più ricche e potenti organizzazioni potevano permettersi un calcolatore elettronico: queste macchine infatti occupavano uno spazio di molte centinaia di metri quadrati, consumavano una quantità di energia elettrica pari a quella di un grosso condominio e richiedevano una costante e specialistica assistenza per poter essere tenuti in esercizio.
Fu proprio in quel periodo, per la precisione nel marzo del 1962, che il "solito", inimitabile Martin Gardner dedicò una puntata della sua mitica rubrica di Giochi Matematici su Scientific American alle "macchine che imparano". (In Italia questo articolo uscì solo parecchi anni dopo, su Le Scienze n. 10 del giugno 1969, in un fascicolo oramai da lungo tempo introvabile). Il tema, piuttosto all'avanguardia per quegli anni, in qualche maniera smitizzava il concetto un po' sinistro del "cervello elettronico" perché mostrava come ci si potesse costruire in casa una semplice macchina in grado di… "imparare" dalla propria esperienza a giocare a filetto! (Parliamo della versione che si fa con carta e penna, che gli americani chiamano Tic-Tac-Toe e qui da noi è noto anche come "tris" o "pallini e crocette"). Non si trattava di un calcolatore, ovviamente: gli unici computer allora disponibili, come dicevo, erano troppo lontani dall'esperienza dell'uomo comune per poter anche solo pensare di poterne parlare in dettaglio. La macchina di Gardner era invece un semplicissimo congegno meccanico che chiunque poteva realizzare con parti facilmente reperibili nei cassetti di casa: poche scatole di fiammiferi e qualche decina di biglie! Certo non si trattava di un sistema sofisticato né tanto meno automatico, e a dire il vero il suo uso era abbastanza macchinoso: tuttavia funzionava, ed anzi la sua incredibile semplicità costruttiva esaltava l'effetto strabiliante che quel congegno suscitava. La "macchina a scatole di fiammiferi" in effetti modificava le sue strategie in base all'"esperienza" fino ad adottare solo quelle ottimali, quindi sotto ogni punto di vista riusciva realmente ad "imparare" a giocare.
Macchine che apprendono
L'articolo di Gardner iniziava con una panoramica sulle "macchine che imparano", ossia sugli esperimenti allora in corso finalizzati alla realizzazione di programmi per computer in grado di apprendere dalla propria esperienza. Prendendo spunto da un famoso lavoro di ricerca svolto da Samuel nel campo del gioco della Dama, Gardner si diceva convinto che i programmi che imparano dall'esperienza sarebbero presto divenuti imbattibili giocatori di dama e scacchi: "Vi sono tutte le ragioni per aspettarsi che una macchina che impari gli scacchi arrivi un giorno, dopo aver giocato migliaia di partite con esperti, a sviluppare l'abilità di un maestro. È anche possibile programmare una macchina da scacchi in modo che giochi continuamente e furiosamente contro se stessa. La sua velocità la metterebbe in grado di acquisire in breve tempo un'esperienza molto superiore a quella di qualsiasi giocatore umano."; specificando peraltro che: "(…) Per quanto mi consta, un programma del genere non è stato ancora preparato per gli scacchi, sebbene siano stati fatti diversi ingegnosi programmi per macchine da scacchi che non imparano.". In effetti questo campo di ricerca si rivelò successivamente poco produttivo, e programmi realmente in grado di imparare (ossia di riconsiderare le proprie azioni traendone giudizi di merito ed indicazioni per i comportamenti futuri) non sono mai stati realmente messi a punto se non in applicazioni estremamente specifiche. Solo oggi ci troviamo di fronte a sistemi che realmente "apprendono", almeno in un certo senso, e sono le reti neurali; ma di queste sicuramente Gardner non poteva avere all'epoca alcuna idea, e quando egli parlava genericamente di "macchina" si riferiva ai concetti classici di automa a stati finiti o di algoritmo procedurale implementato su un computer secondo von Neumann.
Come strumento di sperimentazione personale nel campo delle macchine apprendenti Gardner proponeva dunque il semplice automa a scatole di fiammiferi. Il modello originale, inventato da Donald Michie, era costituito da trecento scatoline di fiammiferi svedesi ed imparava a giocare a filetto. Michie, che non a caso era biologo all'Università di Edinburgo, aveva mutuato il modello della sua invenzione dal classico meccanismo dell'apprendimento nel mondo biologico: aveva infatti sistematizzato un sistema a "premio e punizione", il quale fa sì che i comportamenti "vincenti" vengano favoriti rispetto a quelli "perdenti" in una lunga serie di tentativi ed errori. Ai suoi lettori Gardner suggeriva invece un modello alternativo, di sua realizzazione, dalla costruzione molto più semplice: solo ventiquattro scatoline, per giocare ad un gioco inventato per l'occasione e denominato "esapedone" ("hexapawn" in originale). Tale gioco è in realtà banale in quanto facilmente analizzabile: ma ovviamente il succo del discorso non sta nel gioco in sé, quanto nella possibilità di poter realizzare per esso una semplice macchina che impari a giocarlo.
La macchina a scatoline
Come funziona in generale una macchina a scatoline? Come dicevo prima, il concetto che ne informa la struttura è quello, di derivazione tipicamente biologica, della retroazione mediante premi e punizioni. Il sistema viene addestrato "premiandolo" quando compie azioni vantaggiose e "punendolo" quando invece compie azioni svantaggiose o non desiderate. Certo un conto è insegnare qualcosa ed un organismo vivente, per il quale i concetti di "premio" e "punizione" sono generalmente evidenti, ed un altro è insegnare qualcosa ad una macchina. Vediamo dunque come funziona la cosa.
La macchina di Michie, denominata MENACE come acronimo di "Matchbox Educable Naught and Cross Engine" (cioè "macchina educabile a scatoline per il gioco di pallini e crocette", ma "menace" in inglese vuol dire anche "minaccia"), associava una scatolina ad ogni possibile situazione del gioco del filetto, la quale era effettivamente disegnata sul coperchio della corrispondente scatolina. Per la precisione, dato che l'automa muoveva sempre per primo, le scatoline rappresentavano le sole posizioni corrispondenti alle mosse dispari. Ogni scatolina al suo interno aveva un'estremità sagomata a forma di V e conteneva alcune biglie colorate. Ciascuna biglia era associata ad una delle mosse possibili per la situazione di gioco rappresentata sulla scatolina, e la sagoma a V serviva a facilitare la selezione casuale di una biglia fra le tante: agitando la scatolina chiusa e successivamente aprendola tenendola inclinata, una ed una sola biglia si sarebbe trovata per gravità nel vertice della V e sarebbe stata quindi prescelta. La scatolina corrispondente alla prima mossa conteneva quattro biglie per ciascun colore, quelle per la terza mossa tre, quelle per la quinta mossa due e quelle per la settima mossa una sola per ciascun colore. La nona ed ultima mossa, essendo ovviamente obbligata dal contesto, non veniva esplicitamente codificata nell'"hardware" della macchina.
Il gioco avveniva nel seguente modo. Il giocatore umano avversario della macchina le faceva fare la sua prima mossa estraendo una biglia dalla prima scatolina nel modo prima descritto. Il giocatore umano riportava poi tale mossa sul suo diagramma e provvedeva a fare la sua mossa di conseguenza. A questo punto la mossa della macchina veniva decisa dalla scatolina che rappresentava la situazione attuale del gioco, e la scelta della mossa avveniva col solito sistema. Si procedeva così fino alla fine della partita, avendo cura di lasciare aperta ogni scatolina che avesse contribuito al gioco senza spostare la relativa biglia dal proprio vertice.
Il meccanismo di retroazione, quello che consente alla macchina di "imparare" dalla propria esperienza, si innescava al termine della partita: se la macchina aveva vinto veniva "premiata" aggiungendo a ciascuna scatolina aperta tre biglie del medesimo colore di quella posta nel vertice; se invece aveva perso veniva "punita" eliminando la biglia di vertice da ciascuna scatolina aperta. È chiaro il significato di questo ingegnoso ed elegante meccanismo: alla lunga esso rende sempre più probabili le strategie vincenti e sempre meno probabili quelle perdenti, per cui dopo un certo numero di partite nella macchina non resteranno codificate che le prime ed essa sarà diventata imbattibile. A tutti gli effetti potremmo dire che la macchina ha "imparato" a giocare a filetto, apprendendo sulla base della passata esperienza di gioco quegli schemi comportamentali tali da massimizzare le sue possibilità di vittoria.
Nel suo articolo Gardner riportava anche i dati forniti da Michie su quelli che erano stati i progressi di MENACE lungo un torneo di 220 partite svoltosi nell'arco di due giornate. Com'è facile immaginare, le prime partite vedevano la macchina quasi sempre perdente per ovvia mancanza di conoscenze prestabilite sul gioco. Ma la sua esperienza cresceva costantemente. Dopo diciassette partite MENACE usava solo l'apertura d'angolo, e dalla ventesima partita in poi cominciò a pareggiare sempre più frequentemente. Michie a questo punto cominciò ad adottare schemi di gioco inusuali per "sorprendere" il suo avversario. MENACE rimase spiazzato per un po' ma ben presto, una volta "imparati" anche questi schemi, ricominciò a vincere. Verso la fine del torneo MENACE vinceva mediamente otto partite su dieci, con evidente grande scorno del suo ideatore.
Emuli di MENACE
Una volta compreso il semplice meccanismo generale che sta dietro al funzionamento di MENACE non è difficile, almeno concettualmente, pensare di applicarlo ad altri giochi. I problemi sorgono tuttavia nella pratica, perché ovviamente per costruire una macchina simile per un altro dato gioco bisogna aver in anticipo diagrammato l'albero del gioco stesso, ossia aver costruito l'elenco di tutte le possibili posizioni di gioco: e questo è un compito praticamente impossibile per giochi non banali. Per gli scacchi, ad esempio, non si sa neppure quante siano le posizioni possibili; già le sole prime quattro mosse portano ad un numero così grande che si stima che il numero di posizioni teoricamente raggiungibili nel corso di una intera partita sia dello stesso ordine di grandezza del numero di atomi di idrogeno presenti nell'universo!
Tuttavia è possibile realizzare esempi di macchine sul tipo di MENACE per giochi più semplici, a scopo didattico o di divertimento. La più elementare di tutte fu proposta dallo stesso Gardner come semplificazione di MENACE. Chiamata HER ("Hexapawn Educable Robot", ossia "robot addestrabile all'esapedone" ma anche "lei") e dotata di sole ventiquattro scatoline, questa macchina imparava a giocare all'"esapedone", un gioco ispirato al movimento dei pedoni degli scacchi e disputato su una miniscacchiera di sole tre case di lato. Gardner nell'articolo suggeriva per la sua macchina due diversi sistemi di "insegnamento": uno, dai risultati più veloci ma più incerti, basato sul meccanismo completo a premio e punizione; ed un altro, più lento ma più sicuro, basato sulla sola punizione. In conclusione dell'articolo veniva proposto ai lettori di realizzare una seconda macchina, detta HIM ("Hexapawn Instructable Machine", ossia "Macchina istruibile all'esapedone" ma anche "lui") per farla giocare in torneo contro HER al fine di valutare quale delle due strategie si rivelasse migliore.
Altri giochi si prestano ad essere implementati in macchine a scatoline. Uno realmente classico è il Nim, che è con tutta probabilità il gioco a due giocatori più citato nella teoria dei giochi e nella matematica ricreativa. Secondo Gardner, che citava il lavoro di Stuart Hight dei Bell Labs, è possibile realizzare una macchina per il Nim (nella versione con tre colonne di tre oggetti ciascuna) con sole diciotto scatoline.
È infine possibile semplificare giochi esistenti per renderli accessibili alle capacità di un robot a scatoline. Sempre Gardner propose a tale scopo di "restringere" la Dama ad una scacchiera 4x4 con due pedine per lato: questa "minidama" è certamente meno banale dell'esapedone e dunque può risultare più divertente da giocare.
Dalle scatoline al computer?…
A quarant'anni di distanza dalla loro originale formulazione, tutte queste considerazioni sulle "macchine a scatoline" che imparano dalla propria esperienza possono forse far sorridere: i moderni computer sembrano fare meraviglie, e al loro confronto questi semplici automi meccanici appaiono come un aeroplanino di carta nei confronti dello Shuttle. Eppure esse, al di là dell'indiscusso fascino che portano in sé, hanno anche un'altra valenza ben più profonda: nonostante tutto, infatti, i nostri computer del XXI secolo non hanno ancora… imparato ad imparare! I risultati migliori ottenuti dalle macchine, anche nel campo del gioco, sono infatti legati a programmi di calcolo pre-cablati, nei quali cioè la conoscenza delle regole e delle strategie è inserita a priori, e nei quali non vi è traccia di evoluzione o autoapprendimento. Esistono sì sistemi in grado di apprendere in qualche modo dall'esperienza, le famose reti neurali, ma dopo un iniziale entusiasmo ci si è resi conto che esse non sono adatte a compiti di tipo generale e comunque hanno bisogno di un lungo e attento periodo di training per fornire risultati decenti. Da questo punto di vista le macchine a scatoline si comportano dunque meglio dei nostri moderni supercomputer, i quali sono sì velocissimi ed infallibili ma, ahimé, nonostante tutto ancora inguaribilmente stupidi.
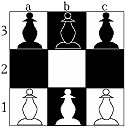 L'esapedone si gioca su una scacchiera 3x3 sulla quale sono posti tre pedoni degli
scacchi per ciascun giocatore, come in figura.
Le mosse sono le stesse del pedone degli scacchi, salvo che non è consentita
la mossa doppia di apertura o la presa "en passant".
Ciascun pedone può dunque avanzare di un passo in avanti se la casa di
fronte è libera, ovvero muoversi di un passo in diagonale, a destra o
a sinistra, per catturare un pedone nemico posto nella casa diagonalmente adiacente.
I pezzi catturati vengono ovviamente eliminati dal gioco.
Il gioco termina quando un giocatore riesce a portare un suo pedone sulla terza
riga della scacchiera oppure a catturare tutti i pezzi avversari.
Per evitare risultati di parità si conviene inoltre che una eventuale
posizione di stallo venga considerata come vittoria del giocatore la cui mossa
lo ha provocato (perché ha bloccato ogni mossa all'avversario).
L'esapedone si gioca su una scacchiera 3x3 sulla quale sono posti tre pedoni degli
scacchi per ciascun giocatore, come in figura.
Le mosse sono le stesse del pedone degli scacchi, salvo che non è consentita
la mossa doppia di apertura o la presa "en passant".
Ciascun pedone può dunque avanzare di un passo in avanti se la casa di
fronte è libera, ovvero muoversi di un passo in diagonale, a destra o
a sinistra, per catturare un pedone nemico posto nella casa diagonalmente adiacente.
I pezzi catturati vengono ovviamente eliminati dal gioco.
Il gioco termina quando un giocatore riesce a portare un suo pedone sulla terza
riga della scacchiera oppure a catturare tutti i pezzi avversari.
Per evitare risultati di parità si conviene inoltre che una eventuale
posizione di stallo venga considerata come vittoria del giocatore la cui mossa
lo ha provocato (perché ha bloccato ogni mossa all'avversario).
Saggio pubblicato su Tangram, rivista di cultura ludica, anno IV n° 11 (settembre 2005)
Copyright © 2005, Corrado Giustozzi. Tutti i diritti riservati.
 Ultima modifica:
Ultima modifica:
Visitatori dal 23 ottobre 2005:
Torna alla Pagina dei saggi pubblicati su Tangram
Vai alla Pagina dei Commenti